Wer kennt das nicht? Man sitzt spätabends vor dem Monitor, die Deadline im Nacken, und möchte nur schnell die Änderungen der Kollegen in das eigene Projekt übernehmen. Plötzlich knallt es im Terminal. Konflikte überall. Genau an diesem Punkt stellt sich die grundlegende Frage nach der richtigen Strategie bei Git Fetch Or Git Pull, denn die Wahl des falschen Befehls führt oft zu unnötigen Stunden voller Fehlersuche. Während der eine Befehl lediglich Informationen sammelt, greift der andere aktiv in deine Dateistruktur ein. Wenn du nicht genau weißt, was unter der Haube passiert, spielst du russisches Roulette mit deiner Versionshistorie. Ich habe in meiner Laufbahn als Entwickler schon ganze Sprints scheitern sehen, weil ein Teammitglied unvorsichtig synchronisiert hat. Es geht hier nicht um Haarspalterei. Es geht um die Kontrolle über deinen Quellcode.
Die Technik hinter der Synchronisation verstehen
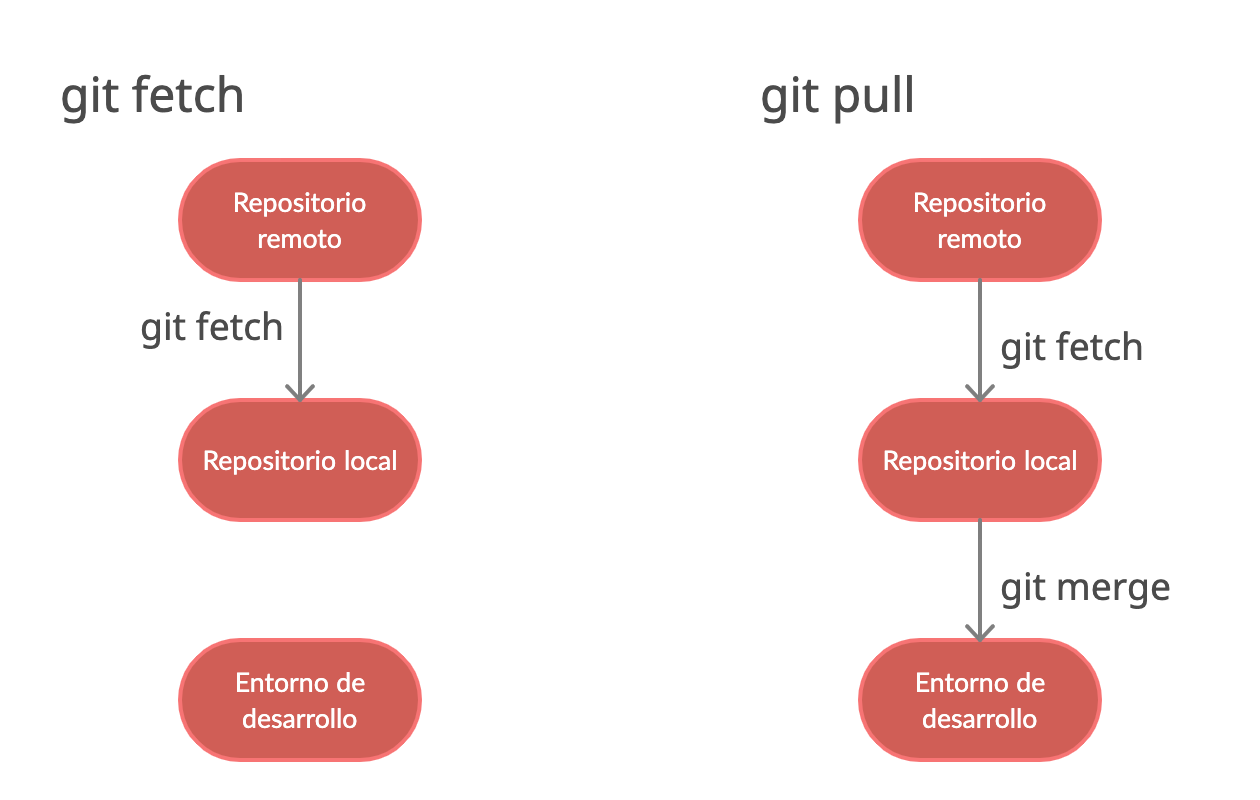
Um zu begreifen, was beim Abgleich mit einem entfernten Repository passiert, muss man sich Git als eine Reihe von Schnappschüssen vorstellen. Dein lokaler Rechner besitzt eine eigene Datenbank, und der Server — etwa bei GitHub oder GitLab — hat eine andere. Wenn du wissen willst, was die anderen heute so getrieben haben, ohne dein eigenes Werk direkt zu gefährden, ist die vorsichtige Variante dein bester Freund. Sie lädt die Metadaten und die neuen Commits herunter, rührt aber deinen aktuellen Arbeitsstand nicht an.
Was passiert im Hintergrund
Sobald du den Befehl zum Abholen der Daten ausführst, kontaktiert dein Client den Server. Er fragt: "Gibt es etwas Neues auf dem Hauptzweig oder in den anderen Branches?" Der Server antwortet mit einer Liste von Objekten. Diese landen in deinem lokalen Speicher unter einem speziellen Verweis, den man Remote-Tracking-Branch nennt. Das ist ein schreibgeschützter Zeiger, der dir zeigt, wo der Server steht. Dein eigener lokaler Branch bleibt davon völlig unberührt. Du kannst dir die Änderungen in Ruhe ansehen, Vergleiche ziehen und entscheiden, ob du sie wirklich integrieren willst.
Sicherheit durch Distanz
Der größte Vorteil dieser Methode liegt in der Risikofreiheit. Es entstehen keine Merge-Konflikte. Es wird kein Code überschrieben. Du gewinnst lediglich Transparenz. In professionellen Teams ist das der Standardvorgang vor jedem größeren Schritt. Man schaut erst, was Sache ist, bevor man blindlings integriert. Wer direkt die Brechstange nutzt, verliert oft den Überblick darüber, welche Änderungen von wem stammen. Das führt zu einer unsauberen Historie, die später kaum noch jemand nachvollziehen kann.
Git Fetch Or Git Pull im direkten Vergleich für den Alltag
Die Entscheidung zwischen diesen beiden Ansätzen ist letztlich eine Frage der Kontrolle. Der kombinierte Befehl, der oft von Anfängern bevorzugt wird, ist im Grunde eine Abkürzung. Er führt zuerst den Download aus und versucht sofort danach, die fernen Änderungen in deinen aktuellen Zweig einzumischen. Das klingt bequem. Ist es auch — solange keine Konflikte auftreten. Aber genau hier liegt der Hund begraben.
Ein typisches Szenario: Du arbeitest an einer CSS-Datei. Ein Kollege hat dieselbe Datei bearbeitet und seine Version bereits hochgeladen. Wenn du nun die kombinierte Aktion ausführst, versucht Git, beide Versionen zu verheiraten. Wenn ihr in denselben Zeilen gearbeitet habt, bricht der Vorgang ab. Du stehst mitten in einem unfertigen Merge. Dein Terminal zeigt kryptische Symbole. Jetzt musst du manuell aufräumen. Hättest du stattdessen nur die Daten geholt, hättest du den Konflikt vorhersehen können.
Die Gefahr der automatischen Zusammenführung
Die Automatisierung neigt dazu, deine lokale Historie mit sogenannten Merge-Commits zu verschmutzen. Das sind diese kleinen Nachrichten wie "Merge branch 'main' of ...". Wenn fünf Leute gleichzeitig so arbeiten, sieht dein Git-Log bald aus wie ein verknäuelter Kopfhörer in der Hosentasche. Es ist schwer zu lesen. Es ist schwer zu debuggen. Wer Wert auf eine lineare, saubere Historie legt, sollte die Finger von der Standardeinstellung des kombinierten Befehls lassen. Es gibt bessere Wege, zum Beispiel das sogenannte Rebase, bei dem deine eigenen Änderungen einfach oben auf die neuen Server-Änderungen draufgesetzt werden.
Wann die Abkürzung sinnvoll ist
Ich will das kombinierte Verfahren nicht verteufeln. Es hat seinen Platz. Wenn du alleine an einem Projekt arbeitest oder weißt, dass niemand sonst an deinen Dateien gefummelt hat, spart es Zeit. Ein kurzer Befehl, und zack, alles ist aktuell. Es ist die Fast-Food-Variante der Softwareentwicklung: schnell, sättigend, aber auf Dauer nicht unbedingt gesund für das Projekt. In einer CI/CD-Umgebung, wo Skripte automatisch den neuesten Stand ziehen müssen, ist dieser Weg oft der pragmatischste. Aber als Mensch vor der Tastatur solltest du bewusster wählen.
Best Practices für saubere Repositories
In der Welt der professionellen Softwareentwicklung bei Unternehmen wie SAP oder in großen Open-Source-Projekten wird penibel auf die Struktur der Commits geachtet. Ein unbedachter Befehl kann die Arbeit von Stunden entwerten, wenn man plötzlich damit beschäftigt ist, Merge-Ruinen zu beseitigen.
- Zuerst immer nur die Daten holen.
- Mit einem Log-Befehl prüfen, was neu dazugekommen ist.
- Die Differenz zum eigenen Stand analysieren.
- Entscheiden, ob ein Merge oder ein Rebase der richtige Weg ist.
Der Rebase-Ansatz als Profi-Lösung
Anstatt die fremden Änderungen in deinen Zweig hineinzuziehen und einen dicken Knoten zu verursachen, kannst du deine Arbeit kurz "anheben" und den neuen Stand des Servers darunterlegen. Danach setzt du deine Arbeit wieder oben drauf. Das Ergebnis ist eine schnurgerade Linie im Verlauf. Das macht die Fehlersuche mit Werkzeugen wie git bisect massiv einfacher. Wenn etwas kaputtgeht, weißt du genau, welcher Commit schuld war, ohne dich durch ein Labyrinth von Zusammenführungen kämpfen zu müssen. Die offizielle Git-Dokumentation bietet hierzu detaillierte Einblicke in die Mechanik des Rebase-Befehls.
Teamkommunikation schlägt Technik
Kein Tool der Welt rettet dich vor schlechter Absprache. Wenn zwei Leute gleichzeitig am selben Kernmodul arbeiten, ist Ärger vorprogrammiert. Git ist ein Werkzeug zur Verwaltung von Änderungen, kein Ersatz für ein kurzes Gespräch oder einen Kommentar im Ticket-System. Ich empfehle, vor großen Änderungen immer kurz im Chat Bescheid zu geben. Ein kurzes "Ich gehe jetzt an die Datenbank-Logik" verhindert oft schon die schlimmsten Kollisionen, noch bevor man überhaupt zum Terminal greift.
Typische Fehler und wie man sie behebt
Jeder macht Fehler. Das ist normal. Wichtig ist, dass man weiß, wie man wieder aus der Sackgasse herauskommt. Einer der häufigsten Patzer ist der "Dirty Worktree". Du hast noch ungespeicherte Änderungen und versuchst, den neuesten Stand vom Server zu ziehen. Git wird dich mit einer Fehlermeldung stoppen. Das ist gut so! Es schützt dich davor, deine unfertige Arbeit zu verlieren.
Den Arbeitsbereich aufräumen
Bevor du irgendetwas vom Server integrierst, sollte dein Arbeitsbereich sauber sein. Entweder du committest deine Änderungen, oder du nutzt den sogenannten Stash. Das ist wie eine kleine Schublade, in die du deine aktuelle Arbeit kurz reinlegst. Danach holst du dir die frischen Daten vom Server, integrierst sie und holst deine Arbeit wieder aus der Schublade hervor. Das klingt nach einem extra Schritt, spart aber langfristig Nerven. Wer das ignoriert, riskiert, dass Git versucht, Dateien zu mischen, die noch gar nicht in einem stabilen Zustand sind.
Wenn der Merge schiefgeht
Falls du doch den kombinierten Befehl genutzt hast und nun in einem Konflikt feststeckst: Keine Panik. Mit dem Befehl --abort kannst du fast jede missglückte Operation rückgängig machen. Es setzt dein Repository auf den Stand vor dem Versuch zurück. Das ist der Moment, an dem du tief durchatmen und es mit der vorsichtigen Methode noch einmal versuchen solltest. Schau dir die Dateien genau an. Moderne Editoren wie VS Code helfen dir dabei, die Unterschiede visuell darzustellen. Nimm dir die Zeit. Wer hier hetzt, baut Fehler ein, die erst Wochen später im Live-Betrieb auffallen.
Strategien für große Teams
In Projekten mit Dutzenden Entwicklern wird die Sache komplexer. Hier arbeitet man oft mit sogenannten Feature-Branches. Man zieht sich eine Kopie des Hauptzweigs, arbeitet isoliert und reicht am Ende einen Pull-Request ein. In diesem Umfeld spielt Git Fetch Or Git Pull eine noch wichtigere Rolle. Du musst deinen Feature-Branch regelmäßig mit dem Hauptzweig synchronisieren, um nicht den Anschluss zu verlieren.
Kontinuierliche Integration
Es ist ratsam, mindestens einmal am Tag die neuesten Informationen vom Server zu holen. So siehst du frühzeitig, wenn sich die Architektur ändert. Wer eine Woche lang in seiner eigenen Blase programmiert, ohne nach links und rechts zu schauen, erlebt am Freitag meist eine böse Überraschung. Die Integration wird dann zum Albtraum. Kleine, häufige Updates sind der Schlüssel zum Erfolg. Das ist wie beim Zähneputzen: Wer es schleifen lässt, braucht später eine teure Wurzelbehandlung.
Werkzeuge und GUIs
Es gibt viele grafische Oberflächen für Git, wie etwa Tower oder GitKraken. Diese Tools visualisieren den Baum deiner Commits. Das hilft enorm, um zu verstehen, was bei einer Synchronisation eigentlich passiert. Aber Vorsicht: Verlass dich nicht blind auf die schicken Knöpfe. Du musst verstehen, was im Hintergrund abläuft. Ein Klick auf "Sync" in einer GUI macht meistens den kombinierten Befehl mit allen seinen Risiken. Ich kenne viele Junioren, die völlig aufgeschmissen sind, wenn die GUI mal nicht funktioniert oder einen Fehler anzeigt, den sie im Terminal mit einem einfachen Befehl lösen könnten.
Die Rolle von Git in der modernen Softwareverteilung
Versionsverwaltung ist heute die Basis für alles. Ohne ein sauberes Git-Management gäbe es keine schnellen Updates für deine Lieblings-Apps. Auch große Plattformen wie GitHub haben den Workflow revolutioniert. Sie bauen auf der Mechanik auf, die wir hier besprechen. Jedes Mal, wenn du auf einen "Merge"-Button im Webbrowser klickst, passiert genau das, was du lokal im Terminal steuerst.
Die Präzision, mit der du deine lokalen Daten mit dem Server abgleichst, bestimmt die Stabilität des gesamten Systems. Wenn die Basis wackelt, bricht das Kartenhaus irgendwann zusammen. Es ist kein Zufall, dass erfahrene Architekten oft Stunden damit verbringen, die Commit-Historie zu bereinigen, bevor ein neues Release freigegeben wird. Ein sauberer Baum ist ein Zeichen für professionelles Handwerk.
Die Wahl des Protokolls
Ob du via HTTPS oder SSH mit dem Server kommunizierst, ist für die Logik der Befehle egal, aber wichtig für deine tägliche Arbeit. SSH ist meist komfortabler, da du nicht ständig dein Passwort eingeben musst. Gerade wenn du die vorsichtige Taktik fährst und öfter mal die Daten abfragst, nervt eine ständige Passwortabfrage kolossal. Richte dir einmal vernünftig deinen SSH-Key ein. Das gehört zum Standard-Setup jedes Entwicklers.
Ausblick auf zukünftige Workflows
Die Entwicklung bleibt nicht stehen. Neue Tools versuchen, die Konfliktlösung noch intelligenter zu gestalten. KI-gestützte Systeme können heute schon einfache Merge-Konflikte selbstständig lösen, indem sie den Kontext des Codes verstehen. Doch solange diese Systeme nicht perfekt sind, bleibt die Verantwortung bei dir. Du bist der Lotse deines Codes. Du entscheidest, welche Änderungen sicher sind und welche nicht. Ein tiefes Verständnis der fundamentalen Befehle ist dein wichtigstes Werkzeug.
Praktische Schritte für dein nächstes Terminal-Abenteuer
Genug der Theorie. Wenn du das nächste Mal vor deinem Projekt sitzt, probier es mal anders. Geh weg von der gewohnten Routine und übernimm die volle Kontrolle. Hier ist der Plan für deinen nächsten Arbeitstag:
- Status prüfen: Bevor du irgendetwas tust, tippe
git status. Dein Arbeitsbereich muss sauber sein. Wenn nicht, räum auf oder schieb die Sachen in den Stash. - Informationen sammeln: Nutze die vorsichtige Variante. Hol dir die Daten vom Server, ohne sie direkt zu mischen. Du siehst jetzt genau, was die anderen gemacht haben.
- Vergleich anstellen: Schau dir mit
git log ..origin/mainan, welche Commits dir lokal fehlen. Lies die Nachrichten der Kollegen. Verstehe, was sie geändert haben. - Die richtige Integrationsmethode wählen: Wenn dein Verlauf linear bleiben soll, nutze
git rebase origin/main. Wenn du lieber einen klaren Schnittpunkt willst und ein Merge-Commit dich nicht stört, dann nutze den klassischen Merge. - Konflikte sofort lösen: Falls es knallt, nimm dir die Zeit. Editiere die Dateien sorgfältig. Teste deinen Code, nachdem du den Konflikt gelöst hast. Vertraue niemals blind darauf, dass nach einem Merge noch alles kompiliert.
- Sauber abschließen: Wenn alles passt, kannst du deine Arbeit hochladen. Deine Kollegen werden dir danken, dass du ihnen keinen kaputten Stand hinterlassen hast.
Git ist ein mächtiges Instrument. Es kann dich befreien oder in den Wahnsinn treiben. Die Entscheidung liegt bei jedem einzelnen Befehl, den du abschickst. Wer die Mechanismen hinter dem Datenabgleich versteht, arbeitet nicht nur schneller, sondern auch entspannter. Es gibt kein schöneres Gefühl als ein perfekt organisiertes Repository, in dem jeder Commit Sinn ergibt und die Historie eine klare Geschichte erzählt. Fang heute damit an, deine Gewohnheiten zu hinterfragen. Es lohnt sich.