Daten sind das neue Gold. Aber Gold bringt dir nichts, wenn es unsortiert in einer dunklen Mine liegt. Wer heute mit Daten arbeitet, merkt schnell: Ohne eine solide Struktur bricht jedes Projekt irgendwann in sich zusammen. Der Befehl SQL To Create A Table bildet das Fundament für fast alles, was wir in der IT-Welt tun. Ob du eine kleine App für dein lokales Café baust oder die Logistik eines DAX-Konzerns steuerst, am Anfang steht immer die Definition deiner Datenstruktur. Ich habe in meiner Laufbahn zu viele Projekte scheitern sehen, weil Entwickler dachten, sie könnten die Tabellenstruktur später „einfach schnell anpassen“. Das funktioniert nie. Eine schlecht geplante Datenbank ist wie ein schiefes Fundament bei einem Haus. Man kann es verkleiden, aber die Risse kommen irgendwann durch.
Die Logik hinter dem Tabellenbau
Bevor du den ersten Befehl tippst, musst du verstehen, was du eigentlich erreichen willst. Eine Datenbanktabelle ist kein Excel-Sheet. In Excel kannst du in eine Zelle schreiben, was du willst. In der Welt der relationalen Datenbanken herrscht Disziplin. Du definierst vorher, welcher Datentyp in welche Spalte gehört. Das klingt einschränkend. Ist es auch. Aber genau diese Einschränkung sorgt für die nötige Qualität. Wenn du eine Spalte für Geburtsdaten anlegst, darf dort kein Text stehen. Punkt. Das schützt dich vor Fehlern, die dich später Nächte kosten könnten.
Datentypen und ihre Tücken
Die Wahl des richtigen Typs entscheidet über die Geschwindigkeit deiner Abfragen. Nimmst du INT für Zahlen oder VARCHAR für Texte? Anfänger machen oft den Fehler, alles als Text zu speichern. Das rächt sich bitterlich. Wenn du versuchst, mathematische Operationen auf Textspalten auszuführen, wird die Datenbank quälend langsam. Bei großen Datenmengen, wie sie etwa bei der Deutschen Bahn für Fahrplandaten anfallen könnten, zählt jedes Byte. Ein BIGINT verbraucht mehr Speicher als ein normaler INTEGER. Wenn du nur Werte bis 100 speicherst, reicht ein TINYINT. Das spart Platz und verbessert die Performance.
Constraints als Schutzschild
Constraints sind die Regeln deiner Tabelle. Der NOT NULL Constraint sorgt dafür, dass ein Feld niemals leer bleibt. Das ist zum Beispiel bei einer E-Mail-Adresse in einer Nutzertabelle sinnvoll. Ohne Mail-Adresse kein Login. Dann gibt es den UNIQUE Constraint. Er verhindert doppelte Einträge. Stell dir vor, zwei Kunden hätten die gleiche Kundennummer. Das totale Chaos wäre vorprogrammiert. Ich nutze Constraints bei jedem Entwurf. Sie fangen Fehler ab, bevor sie in die Logik deiner Anwendung wandern.
SQL To Create A Table in der täglichen Praxis
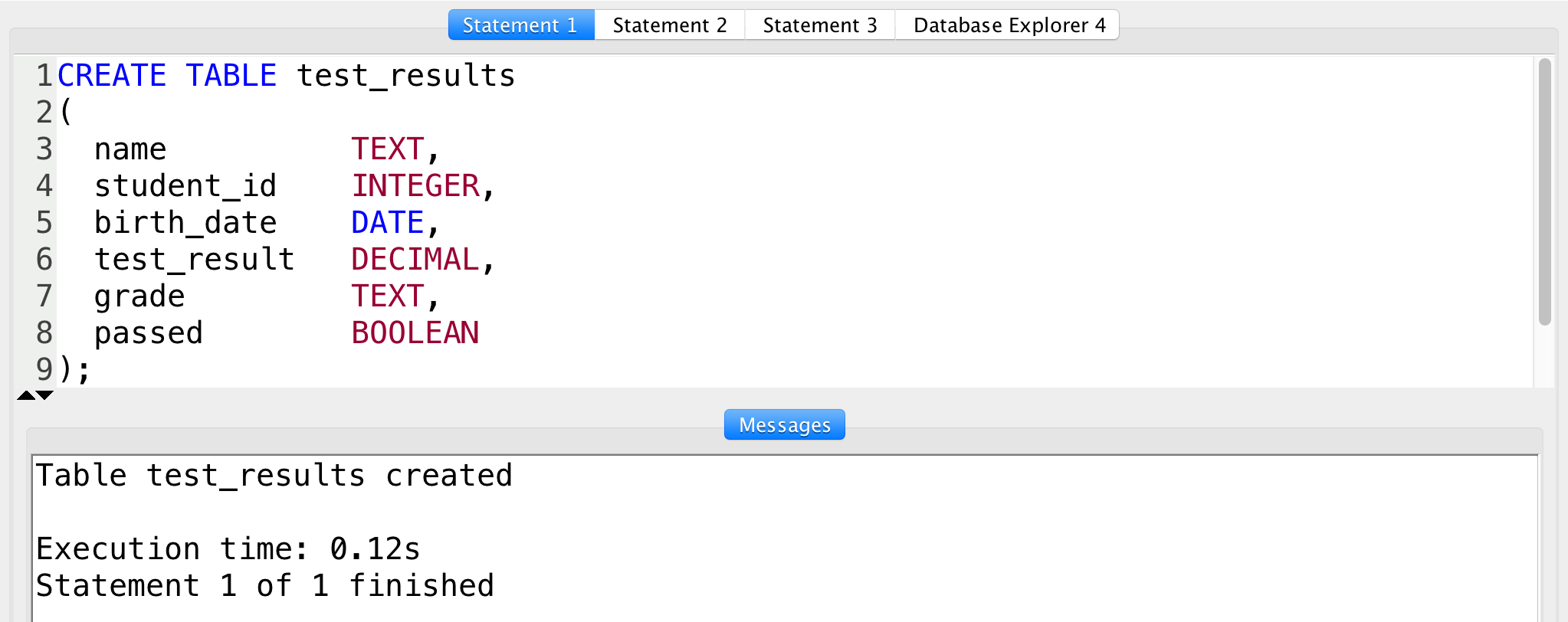
Schauen wir uns an, wie man das konkret umsetzt. Die Syntax ist eigentlich simpel. Du startest mit der Anweisung, nennst den Namen der Tabelle und listest dann die Spalten in Klammern auf. Hier trennt sich die Spreu vom Weizen. Profis achten auf eine klare Benennung. Nutze keine Umlaute. Vermeide Leerzeichen. Ein Name wie kunden_bestellungen_2024 ist klar und verständlich. Ein Name wie tabelle1 ist ein Ticket in die Hölle der Wartbarkeit.
Primärschlüssel sind Pflicht
Jede Tabelle braucht einen Primärschlüssel. Das ist der eindeutige Identifikator für eine Zeile. Meistens ist das eine ID-Spalte, die sich automatisch hochzählt. Ohne diesen Schlüssel kannst du Zeilen nicht gezielt ansprechen. Es ist wie eine Hausnummer. Ohne Nummer findet der Postbote das Haus nicht. In SQL nutzt man dafür oft AUTO_INCREMENT oder in PostgreSQL SERIAL. Das nimmt dir die Arbeit ab, bei jedem neuen Eintrag selbst eine Nummer zu vergeben.
Fremdschlüssel und Beziehungen
Echte Magie entsteht, wenn Tabellen miteinander reden. Ein Fremdschlüssel verweist auf den Primärschlüssel einer anderen Tabelle. So verbindest du Kunden mit ihren Bestellungen. Das nennt man referenzielle Integrität. Wenn du einen Kunden löschst, der noch offene Bestellungen hat, verhindert die Datenbank das. Zumindest, wenn du die Regeln richtig gesetzt hast. Das verhindert sogenannte „Datenleichen“, also Informationen, die keinen Bezugspunkt mehr haben.
Häufige Fehler beim Datenbankdesign
Ich habe schon Datenbanken gesehen, die ahen aus wie ein verknotetes Wollknäuel. Der größte Fehler ist die mangelnde Normalisierung. Leute versuchen oft, zu viele Informationen in eine einzige Tabelle zu quetschen. Sie speichern die Adresse direkt beim Kunden. Was passiert aber, wenn der Kunde zwei Adressen hat? Eine Lieferadresse und eine Rechnungsadresse? Schon fängt das Gebastel an. Man fängt an, Spalten wie adresse_2 hinzuzufügen. Das ist schlechter Stil.
Die Falle der redundanten Daten
Redundanz ist der Feind. Wenn du den Namen eines Herstellers in jeder einzelnen Produktzeile speicherst, hast du ein Problem. Wenn sich der Name ändert, musst du tausende Zeilen aktualisieren. Ändert man eine Zeile nicht, ist der Datenbestand inkonsistent. Die Lösung ist eine separate Tabelle für Hersteller. In der Produkttabelle speicherst du nur noch die ID des Herstellers. Das ist sauber. Das ist effizient.
Performance-Killer Indizes
Viele denken, Indizes machen alles schneller. Das stimmt nur bedingt. Ein Index ist wie ein Register am Ende eines Buches. Er hilft beim Suchen. Aber jedes Mal, wenn du etwas ins Buch schreibst, musst du auch das Register aktualisieren. Zu viele Indizes machen Schreibvorgänge langsam. Man muss hier eine Balance finden. Überlege genau, nach welchen Spalten du oft suchst. Das sind die Kandidaten für einen Index. Meistens sind das Fremdschlüssel oder Datumsspalten.
Moderne SQL Dialekte im Vergleich
Nicht jedes SQL ist gleich. MySQL, PostgreSQL, Oracle und Microsoft SQL Server haben alle ihre Eigenheiten. Während die Grundstruktur von SQL To Create A Table überall fast identisch ist, liegen die Unterschiede im Detail. PostgreSQL ist bekannt für seine Strenge und die Unterstützung komplexer Datentypen. MySQL ist der Klassiker für Webanwendungen, schnell und unkompliziert. Wer im Enterprise-Umfeld arbeitet, kommt oft an Oracle nicht vorbei. Hier geht es um massive Skalierbarkeit und Support-Garantien.
Cloud-Datenbanken und Serverless
Heute betreiben viele ihre Datenbanken nicht mehr auf eigenen Servern. Anbieter wie AWS oder Google Cloud bieten verwaltete Dienste an. Das ändert nichts an der Logik der Tabellenerstellung. Es nimmt dir nur die Sorge um die Hardware ab. Dennoch musst du deine Tabellen klug planen. In der Cloud zahlst du oft für den Speicherplatz und die Rechenleistung. Eine ineffiziente Tabelle kostet hier echtes Geld. Jedes unnötige Feld treibt die Rechnung nach oben.
NoSQL als Alternative
Manchmal ist SQL nicht die richtige Wahl. Wenn du völlig unstrukturierte Daten hast, könnte MongoDB oder eine andere NoSQL-Lösung besser passen. Aber Vorsicht. Viele springen auf den NoSQL-Zug auf, weil es modern klingt. Am Ende stellen sie fest, dass ihre Daten doch relational sind. Dann versuchen sie, relationale Logik in NoSQL nachzubauen. Das ist schmerzhaft und ineffizient. Bleib bei SQL, wenn deine Daten klare Beziehungen zueinander haben. Das ist bei 90 % der Geschäftsanwendungen der Fall.
Sicherheit und Berechtigungen
Ein oft vergessener Aspekt beim Erstellen von Tabellen ist die Sicherheit. Wer darf die Tabelle sehen? Wer darf Daten einfügen? In einer professionellen Umgebung erstellst du die Tabelle nicht einfach und lässt jeden darauf zugreifen. Du nutzt das Rollenkonzept der Datenbank. Der Webserver bekommt nur Leserechte und Schreibrechte für bestimmte Tabellen. Er darf niemals Tabellen löschen oder die Struktur ändern. Das ist die Aufgabe des Administrators.
SQL-Injection verhindern
Obwohl das Erstellen der Tabelle selbst nicht direkt mit SQL-Injection zu tun hat, legt das Design der Tabelle den Grundstein für sichere Abfragen. Nutze keine Datentypen, die mehr erlauben als nötig. Wenn in ein Feld nur Zahlen gehören, nimm einen numerischen Typ. Das erschwert es Angreifern, Schadcode einzuschleusen. Sicherheit beginnt beim Tabellendesign. Wer hier schlampt, öffnet Tür und Tor für Angriffe. Das Bundesamt für Sicherheit in der Informationstechnik bietet hierzu viele hilfreiche Leitfäden an.
Backups und Wiederherstellung
Was passiert, wenn du eine Tabelle versehentlich löschst? Ohne Backup bist du erledigt. Jede seriöse Strategie zur Datenverwaltung beinhaltet regelmäßige Backups. Aber Vorsicht. Ein Backup ist nur so gut wie der letzte Wiederherstellungstest. Ich habe Firmen erlebt, die jahrelang Backups machten, nur um im Ernstfall festzustellen, dass die Dateien korrupt waren. Teste deine Wiederherstellung regelmäßig. Das gehört zum Handwerk dazu.
Praxistipps für den Entwurf
Wenn ich eine neue Datenbank entwerfe, greife ich meistens erst zu Stift und Papier. Oder zu einem digitalen Whiteboard. Zeichne die Tabellen auf. Ziehe Linien zwischen den Tabellen, um Beziehungen darzustellen. Das hilft dir, Logikfehler zu finden, bevor du Code schreibst. Erst wenn das Diagramm steht, fange ich mit der Implementierung an. Das spart Zeit und Nerven.
Dokumentation ist kein Luxus
Schreibe Kommentare in deinen SQL-Code. Warum hast du diesen Datentyp gewählt? Was bedeutet die Abkürzung im Spaltennamen? In sechs Monaten wirst du dich nicht mehr daran erinnern. Deine Kollegen werden es dir danken. Eine gute Dokumentation ist das Markenzeichen eines Profis. Es gibt Tools, die aus deinen Tabellendefinitionen automatisch eine Dokumentation generieren. Nutze sie.
Namenskonventionen einhalten
Einige Teams nutzen Präfixe wie tbl_ für Tabellen oder col_ für Spalten. Ich halte das für unnötigen Ballast. Eine Tabelle sollte einfach so heißen, was sie enthält. Benutzer ist besser als tbl_benutzer. Wichtig ist nur, dass ihr euch im Team einigt. Nichts ist schlimmer als ein Mix aus deutschen und englischen Begriffen oder unterschiedliche Schreibweisen wie CamelCase und snake_case. Konsistenz ist alles.
Die Rolle von SQL in der Ära von KI
Man könnte meinen, dass künstliche Intelligenz SQL überflüssig macht. Das Gegenteil ist der Fall. KI-Tools wie ChatGPT können zwar SQL-Code schreiben, aber sie brauchen präzise Anweisungen. Wenn du nicht verstehst, wie man eine Tabelle richtig aufbaut, kannst du der KI nicht sagen, was sie tun soll. Du musst das Ergebnis prüfen können. Ein von einer KI generiertes Tabellendesign kann auf den ersten Blick gut aussehen, aber bei hoher Last kläglich versagen. Das menschliche Fachwissen bleibt die letzte Kontrollinstanz.
Automatisierung von Migrationen
In modernen Entwicklungszyklen erstellt man Tabellen selten manuell direkt auf der Produktionsdatenbank. Man nutzt Migrationstools. Diese Werkzeuge tracken Änderungen an der Datenbankstruktur in Versionierungssystemen wie Git. So kann jeder im Team die gleiche Struktur lokal aufbauen. Das verhindert das klassische „Bei mir auf dem Rechner funktioniert es aber“. Migrationen machen den Prozess nachvollziehbar und sicher.
Testdaten generieren
Sobald die Tabelle steht, brauchst du Daten zum Testen. Es gibt Tools, die Millionen von realistischen Datensätzen erzeugen. Das ist wichtig, um die Performance zu testen. Eine Abfrage, die bei 10 Zeilen schnell ist, kann bei 10 Millionen Zeilen Minuten dauern. Erst unter Last zeigt sich, ob dein Design wirklich gut ist. Spare nicht an dieser Phase. Ein System, das am Tag der Liveschaltung zusammenbricht, ist ein Albtraum.
Strategische Schritte für dein nächstes Projekt
Du stehst jetzt vor der Aufgabe, deine eigene Datenbank zu strukturieren. Fang klein an, aber denke groß. Hier sind die nächsten Schritte, die du gehen solltest, um erfolgreich zu sein.
- Erstelle ein Entity-Relationship-Diagramm (ERD). Visualisiere deine Daten und deren Beziehungen zueinander auf Papier oder mit einem Tool wie Draw.io.
- Wähle die Datentypen mit Bedacht. Frage dich bei jeder Spalte: Was ist der kleinstmögliche Typ, der diese Daten sicher speichern kann?
- Setze von Anfang an auf Constraints. Verlasse dich nicht darauf, dass deine Applikationslogik alle Fehler abfängt. Die Datenbank ist die letzte Verteidigungslinie.
- Nutze eine Versionsverwaltung für deine SQL-Skripte. Behandle deine Datenbankstruktur wie Code.
- Plane Indizes erst nach den ersten Lasttests. Verstehe zuerst, wie deine Anwendung die Daten abfragt, bevor du die Datenbank mit Indizes überlädst.
- Dokumentiere deine Entscheidungen. Ein einfaches "Warum" neben einer ungewöhnlichen Spaltendefinition kann später Stunden an Recherche sparen.
Wer diese Regeln befolgt, baut Systeme, die stabil laufen und mit den Anforderungen wachsen. SQL ist kein Relikt aus der Vergangenheit. Es ist die Sprache, die unsere digitale Welt im Innersten zusammenhält. Wer sie beherrscht, hat die volle Kontrolle über seine Daten. Und Kontrolle ist in der IT-Welt fast so viel wert wie die Daten selbst. Geh es strukturiert an, sei präzise und achte auf die Details. Deine zukünftigen Nutzer und deine Kollegen werden es dir danken. Man lernt SQL nicht an einem Tag perfekt, aber mit jedem klug gewählten Tabellendesign wirst du besser. Es lohnt sich, hier Zeit zu investieren. Viel Erfolg beim Bau deiner nächsten Datenbank.